


If you have reached the end of a systematic review and spent days reformatting extracted data to fit your intended final workbook structure, you already understand the problem Index Tables are designed to solve.
Most extraction workflows are built around the act of collecting data rather than the act of using it. The consequence is predictable: baseline characteristics, efficacy outcomes, and adverse event data accumulate in separate spreadsheets that must later be reconciled manually, often with inconsistent arm labels, repeated identifiers, and column headers that bear only a passing resemblance to the evidence table sitting in your submission template. By the time the data reaches the analyst or medical writer, restructuring is unavoidable. Index Tables close that gap by making extraction structure reflective of output structure and uniting the arms and subgroups across all data collected.
Clinical Data Is Relational. Flat Tables Are Not.
A single study may report efficacy outcomes, safety events, and baseline demographics across multiple treatment arms, at multiple timepoints, for different subpopulations, at a range of timepoints. The relationship between a study arm or group and its associated data is precisely what gives that data meaning in an evidence synthesis context. When that relationship is managed through convention rather than structured relationships, the process introduces fragility and disharmony at every step.
Index Tables handle this by enabling pre-population of study-level information, leading to two levels of extraction. The first is the index: a defined set of columns that establish the identity of each row. For example each row could represent some combination of Study Arm, Intervention, Dose or Regimen, and/or Number of Patients. These columns are configured once and inherited automatically by every sub-table, functioning the way a foreign key operates in a relational database. Every data point can be traced back to exactly one study arm by design, not convention.
The second layer consists of sub-tables, one per domain (e.g. “Overall Survival” or “Weight Loss”). A typical configuration for an RCT-based review might include an Efficacy Outcomes sub-table capturing endpoint, timepoint, baseline value, percentage change from baseline, treatment difference, and p-value; a Safety sub-table capturing adverse event type, incidence, severity, and discontinuation rate; and a Demographics sub-table capturing age, sex distribution, BMI, and relevant comorbidities. Each sub-table inherits the index columns automatically, so arm identity is structurally preserved across every domain without redundant re-entry.
Setting Up an Index Table
Configuration begins in the same place as a standard Tag Table. In edit tag mode, select the tag you want to attach the Index Table to, confirm the tag details, and select “Index Table” under Content Mode.
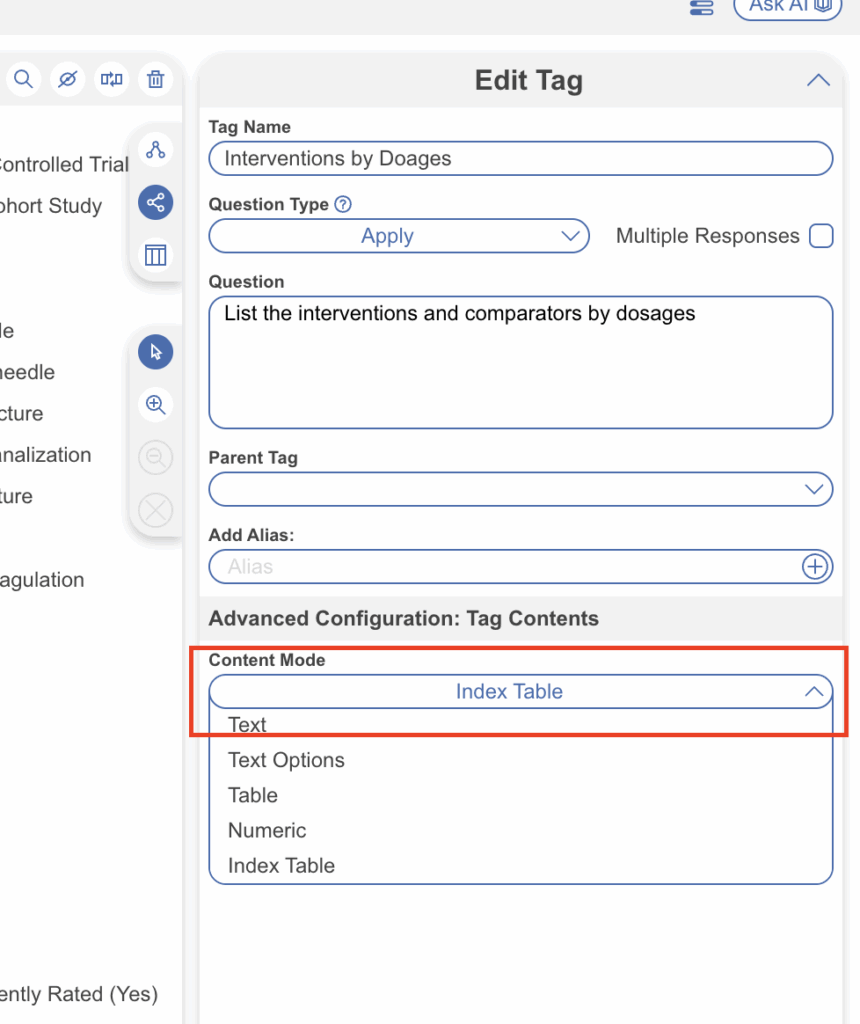
From there, the workflow has three steps. First, define the index columns. These should be limited to fields that apply equally across every sub-table: Study Arm, Intervention, Dose, and N to use our previous examples. Optionally, where arm names and intervention labels are known in advance, configure them as dropdown options rather than free text. Consistent naming enforced at the point of extraction is substantially easier to maintain than cleaning inconsistencies after the fact.

Second, create the sub-tables. Each sub-table represents a distinct data domain and requires only its domain-specific columns to be configured, since the index columns are inherited. Columns are displayed left to right in extraction and export in the order they are listed during configuration, and can be reordered at any time without affecting existing data.
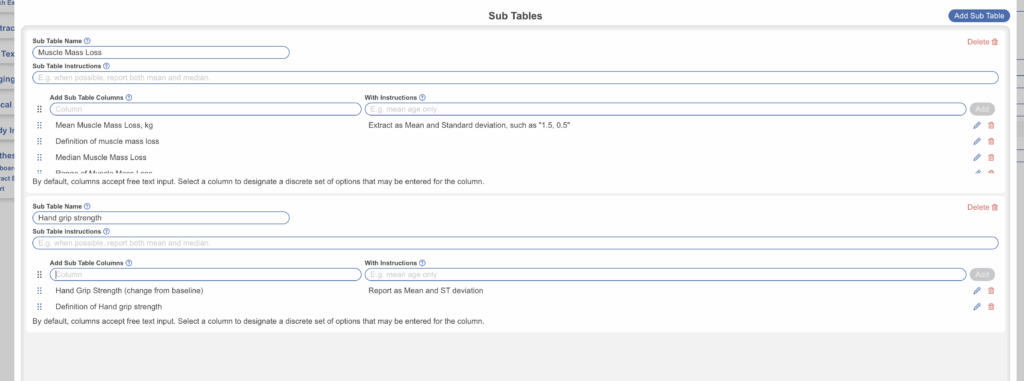
Third, move to the Tagging module to begin extraction. The Index Table displays with the index columns on the left as a persistent anchor, and the active sub-table accessible via tabs to the right. Fill in the index once per study arm, then populate each sub-table for that arm. Column headers and dropdown options can be edited on the fly by selecting the header directly in the extraction view.
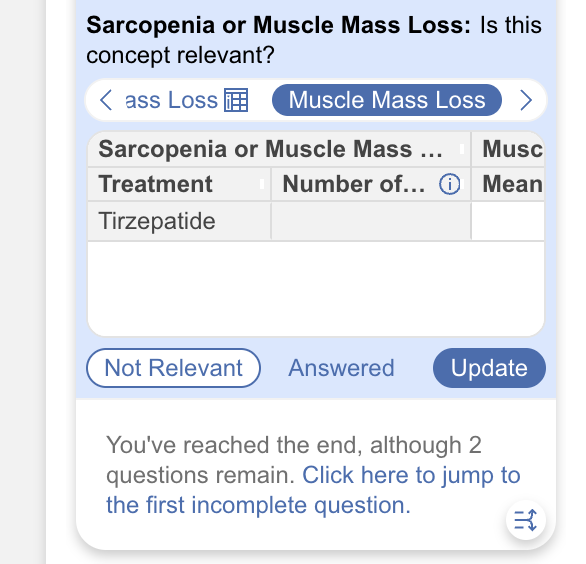
Index Tables are fully supported by Nested Knowledge’s AI extraction via Adaptive Smart Tags, which means the LLM can populate sub-table columns directly from full-text sources. The quality of AI extraction is directly responsive to the precision of your prompting: tag names, column headers and instructions, as well as Tag ‘Questions’ should be written with clear, logical extraction instructions to the model on exactly what format the output should take. A column labelled “Overall Survival (median)” with a tag question specifying “report the exact numerical value with appropriate measure of variance” will produce substantially cleaner AI output than a generic label. Once a configuration has been validated and shown to produce high-fidelity extraction, it can be saved as a Tag Template and reused across projects.
Solve Formatting Problems at the Beginning
Evidence tables such as those found in HTA dossiers and CER submissions often follow defined formats. The expectation is generally one row per study arm, with columns spanning efficacy, safety, and baseline data in a structure that reviewers can navigate directly. Meeting that expectation with data extracted into a different structure means someone, somewhere, spends significant time bridging the gap.
Because Index Table sub-tables are configured to match the target output format from the outset, column headers correspond directly to those in the submission template. There is no intermediate restructuring phase. When exported via Dashboard, Index Tables combine into a single wide-format sheet. The data that enters the Index Table during extraction is the data that appears in the dossier.
This is not a minor efficiency gain. Every manual restructuring step carries error risk, so pre-specified and automated handling of data streamlines extraction. Reconciling arm labels across three spreadsheets, mapping timepoint columns named differently across extraction files, correcting a row attributed to the wrong comparator: these are the kinds of errors that surface late, under deadline, in documents that carry regulatory weight.
A Few Principles Worth Following
Complex data extraction has some principles to keep in mind:
- Keep the index lean. Over-indexing creates redundancy rather than clarity, and columns that only matter for one sub-table belong in that sub-table, not in the index.
- Think of your output. Design each sub-table around the column structure of your target output, and test the full configuration against a single representative study before scaling across the review.
- Plan for flexibility. For teams managing multiple projects or submission types, the sub-table structure can be adapted to different dossier formats without changing the underlying index, making the extraction logic reusable even when the output format varies.
The right time to solve the formatting problem is before extraction begins, not after it ends. Index Tables make that possible.
To see how Index Tables fit into a full evidence synthesis workflow, book a demo with the Nested Knowledge team.
A blog about systematic literature reviews?
Yep, you read that right. We started making software for conducting systematic reviews because we like doing systematic reviews. And we bet you do too.
If you do, check out this featured post and come back often! We post all the time about best practices, new software features, and upcoming collaborations (that you can join!).
Better yet, subscribe to our blog, and get each new post straight to your inbox.

How Smart Study Type Tags Are Reinventing Evidence Synthesis
One of the features of Core Smart Tags is Smart Study Type – this refers to our AI system that automatically categorises the study type
