


Blog
How Smart Study Type Tags Are Reinventing Evidence Synthesis
One of the features of Core Smart Tags is Smart Study Type – this refers to our AI system that automatically categorises the study type
Systematic literature reviews (SLRs) are the backbone of Health Economics and Outcomes Research (HEOR), playing a vital role in Health Technology Assessments (HTAs). However, the vast quantity of research publications can turn the initial screening of abstracts into a time-consuming roadblock. Nested Knowledge’s (NK) Robot Screener is an AI tool poised to revolutionize this process, saving researchers time and ensuring high-quality evidence informs critical HTA decisions.
Two recent studies, one internal validation authored by the Nested Knowledge team and one independent study / external validation, have shed light on Robot Screener’s effectiveness in the diverse types of review needed to support both publishable SLRs and HTA. These studies employed robust methodologies for direct human-vs-AI performance across dozens of diverse reviews, providing compelling evidence for its role in streamlining HEOR-focused SLRs.
Methodology Matters: Assessing Recall and Precision
Both studies assessed Robot Screener’s performance by comparing its inclusion/exclusion decisions with those of human reviewers. The internal study focused on NK-published SLRs, analyzing over 8,900 abstracts across clinical, economic, and mental health research. The external study, specifically targeting HEOR topics for HTAs, included previously completed reviews on infectious diseases, neurodegenerative disorders, oncology, and more.
A key metric evaluated in both studies was Recall, which reflects the tool’s ability to identify relevant studies. Precision, on the other hand, measures the proportion of studies flagged by the tool that are relevant. These metrics provide a comprehensive picture of Robot Screener’s effectiveness in both flagging studies that are likely to be includable or of interest and thus preventing ‘missed’ studies (Recall) and in excluding studies that are likely outside of a review’s purview to save the effort of the adjudicator in excluding these non-relevant studies (Precision).
Internal Study: High Recall Prioritizes Comprehensiveness
The internal study conducted by Nested Knowledge was performed on a set of 19 reviews that employed Robot Screener as a second reviewer in a Dual Screening process (see Figure). Robot Screener achieved a recall rate of 97.1%, significantly outperforming human reviewers (94.4%). This indicates that Robot Screener effectively captured a higher proportion of relevant studies. However, its precision rate of 47.3% fell short of human reviewers (86.4%). In effect, while Robot Screener missed significantly fewer includable studies, it sent forward significantly more studies that needed to be triaged out during adjudication.
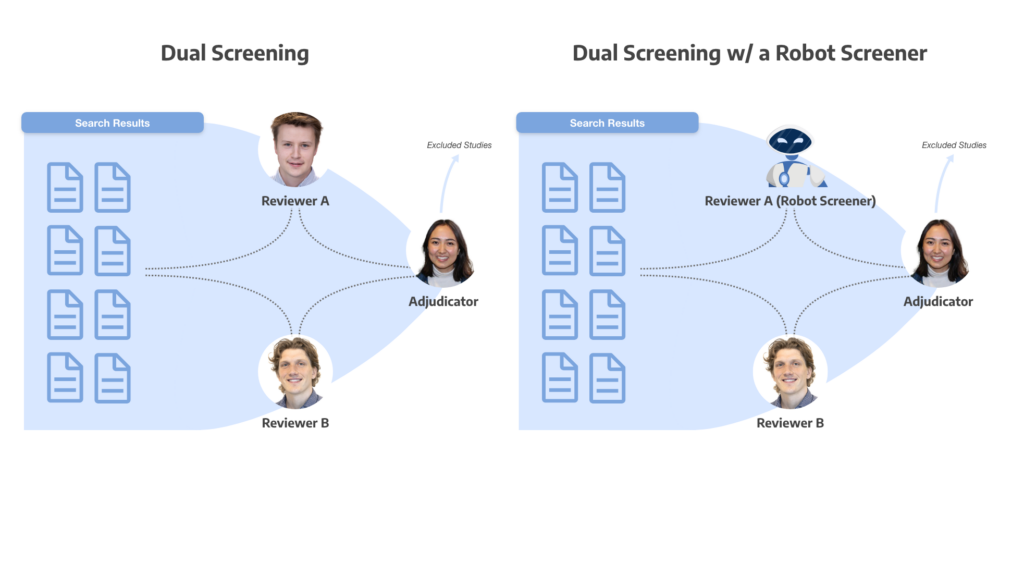
This difference reflects a strategic design choice. Robot Screener prioritizes high recall to ensure no crucial studies are missed in the initial screening phase. The adjudication stage then focuses on the flagged articles, maintaining the rigor of the SLR process and ensuring that irrelevant articles are screened out even when recommended for inclusion by either the human or Robot Screener. This prioritization of comprehensiveness is particularly valuable in HEOR, where missing relevant studies could lead to incomplete HTAs with potentially significant implications for interpretation.
External Study: Comparable Recall with Focus on Up-to-Date Evidence
The external study, conducted by Cichewicz et al., designed to simulate updating existing HEOR-based SLRs, also produced promising results. Mean and SD of recall and precision was measured with values ranging from 0 to 1 and higher values indicate better recall or precision. Robot Screener’s Recall rate (0.79 ± 0.18) was comparable to human reviewers (0.80 ± 0.20). While overall Recall for both humans and Robot Screener were lower than in the internal study, this likely indicates different proportions of final-included studies, and the consistency of Robot Screener in matching or exceeding Recall in HEOR-focused SLRs shows that the tool is generalizable across disciplines. Furthermore, the Cichewicz et al. study, rather than employing Robot Screener throughout the entire initial review, focused on updates, demonstrating Robot Screener’s ability to efficiently identify potentially relevant studies even when refreshing older reviews with new research.
As with the internal study, Robot Screener’s precision rate (0.46 ± 0.13) was lower than human reviewers (0.77 ± 0.19) in Cichewicz et al. However, the study’s conclusions emphasized that the time saved through efficient screening outweighs the need for additional human effort to adjudicate these “false positives.” Moreover, the low false negative rate (2%) for Robot Screener underscores its effectiveness in minimizing the risk of excluding truly relevant studies.
Large Language Models for Screening and “Recall-first” philosophy
Comparing Robot Screener to human screeners is helpful in determining workflows that can improve accuracy and timelines in SLR. However, Robot Screener, as a machine learning algorithm, depends on project-specific training on users’ decisions. A recent study by Tran et al. (2024) explored a related question, the effectiveness of GPT-3.5 Turbo models for title and abstract screening in five systematic reviews without any project-specific training. In different configurations, GPT-3.5 achieved high sensitivity (recall) rates, ranging from 81.1% to 99.8% depending on the optimization rule, though the specificity ranged from as low as 2.2% to as high as 80.4%. This indicates that Large Language Models (LLMs) may show promise for screening without the need for training data, but that overall accuracy ranged widely based on whether the model is optimized for maximizing recall vs. maximizing ‘correct’ exclusions.
We look forward to the further development of both machine learning and LLM approaches to screening, and this publication also drives home that it is likely as important to optimize the thresholds used by models as it is to train or tune them correctly–the thresholding itself had a far greater impact on recall and specificity in Tran et al. To paraphrase Cichewicz et al., a more conservative approach (prioritizing and optimizing recall, so that no includable study is missed) mitigates the risk of non-comprehensiveness, and when used in a dual-screening approach, does not compromise the final review screening accuracy despite presenting lower precision (and specificity). Thus, approaches that include human adjudication and maximize recall can provide AI-assisted screening while maintaining review quality.
Confidence in Your HEOR Research: The Power of Robot Screener
These studies highlight the significant benefits Robot Screener offers researchers conducting HEOR-focused SLRs within Nested Knowledge. Here’s a quick recap of the key takeaways:
The Future of SLR Research: A Collaborative Approach
These validation studies pave the way for adoption of Robot Screener in adjudicated systems with human and AI collaborative screening, bringing time savings but also providing different strengths, with humans outperforming in Precision and AI potentially providing higher Recall. This also paves the way for a future research exploring the use of Robot Screener and other AI screening tools in different configurations, with different oversight or workflows, and in different review types beyond publishable SLRs and SLRs for HTA.
By embracing Robot Screener, researchers can leverage the power of AI to streamline their workflows, ensure high-quality evidence informs SLRs and evidence synthesis generally, and ultimately contribute to better evidence synthesis and health outcomes.
Yep, you read that right. We started making software for conducting systematic reviews because we like doing systematic reviews. And we bet you do too.
If you do, check out this featured post and come back often! We post all the time about best practices, new software features, and upcoming collaborations (that you can join!).
Better yet, subscribe to our blog, and get each new post straight to your inbox.
One of the features of Core Smart Tags is Smart Study Type – this refers to our AI system that automatically categorises the study type
