When a clinical trial evaluates a novel drug or uncovers a change in medical best practices, the results are often published in a widely-read scientific journal, like JAMA, Lancet, or the NEJM. Even trials that don’t unveil the next blockbuster drug are vital. Trials showing no effect compared to placebo, so-called “negative” or inconclusive trials, shape the evidence landscape as much as the splashy headlines.
These trials lie buried in less popular sources: clinical trial registries. While physicians might skim through an issue of JAMA each month, no physician has time to sift through all trial registries!
Instead, systematic reviewers and guideline groups must combine extant medical evidence from trials and condense the results into a publication or recommendation. Thankfully, tools for retrieving trial contents alleviate this burden.
Why Include Clinical Trials?
By failing to include clinical trial records, researchers may overlook data that is critical to their review. Trials reporting no effect and trials terminated early often do not reach journal pages, but many of them are searchable in online trial registries. Excluding “negative” and no-effect findings distorts the evidence. To effectively identify all relevant trials for a systematic review, experts recommend searching the US-maintained ClinicalTrials.gov registry to access key data.
Need for PDFs
A variety of review tools integrate directly with ClinicalTrials.gov, but a workflow problem remains: ClinicalTrials.gov records are not available as PDFs. In a systematic review, researchers and machines alike extract data from PDFs to evaluate therapies and compare outcomes. Pre-prints, books, and scientific articles bounce across the internet as PDFs, but trial registries provide data in other formats, like HTML and JSON.
ClinicalTrials.gov records do not always correspond one-to-one with published results in a journal, and not all trials are published, as publication is a costly, time-intensive process not feasible for all research groups. Some trials include links to related full text publications, but trials frequently have multiple publications–making it unclear which one to include in a review. When a trial has no associated publication, the results must be accessed through a webpage on a trial registry.
While PDFs are the universal medium of scientific communication, ClinicalTrials.gov records cannot be exported as a PDF. For researchers, this means endless clicking, printing, and stitching together web pages just to get a usable document.
How can researchers identify full texts for unpublished clinical trials?
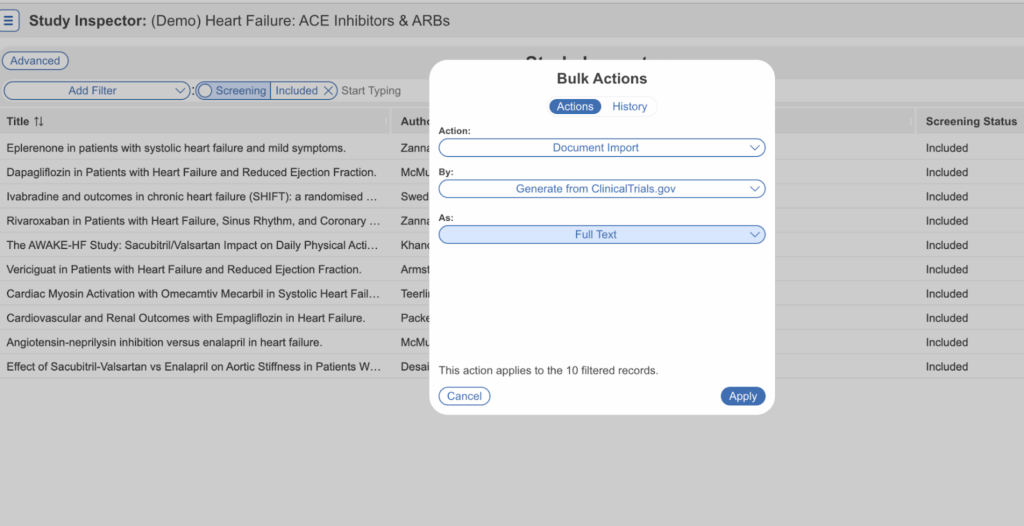
To effectively capture evidence from unpublished trials, systematic-reviewers must include ClinicalTrials.gov reports in their data extraction process. As more researchers adopt AI with oversight, trial data needs to be available in formats understandable and accepted by both Large Language Models and people: PDFs. Nested Knowledge helps researchers surface, organize, and extract clinical trial information in PDFs. Presently, reviewers export clinical trial data by navigating across many trial tabs, printing each tab, and combining the webpages, adding to the tedium that accompanies many systematic reviews.
To achieve parity with published research articles (and to reduce the global burden of combining PDFs), Nested Knowledge’s tool converts ClinicalTrial.gov records to PDFs for you!