
Blog
How Smart Study Type Tags Are Reinventing Evidence Synthesis
One of the features of Core Smart Tags is Smart Study Type – this refers to our AI system that automatically categorises the study type



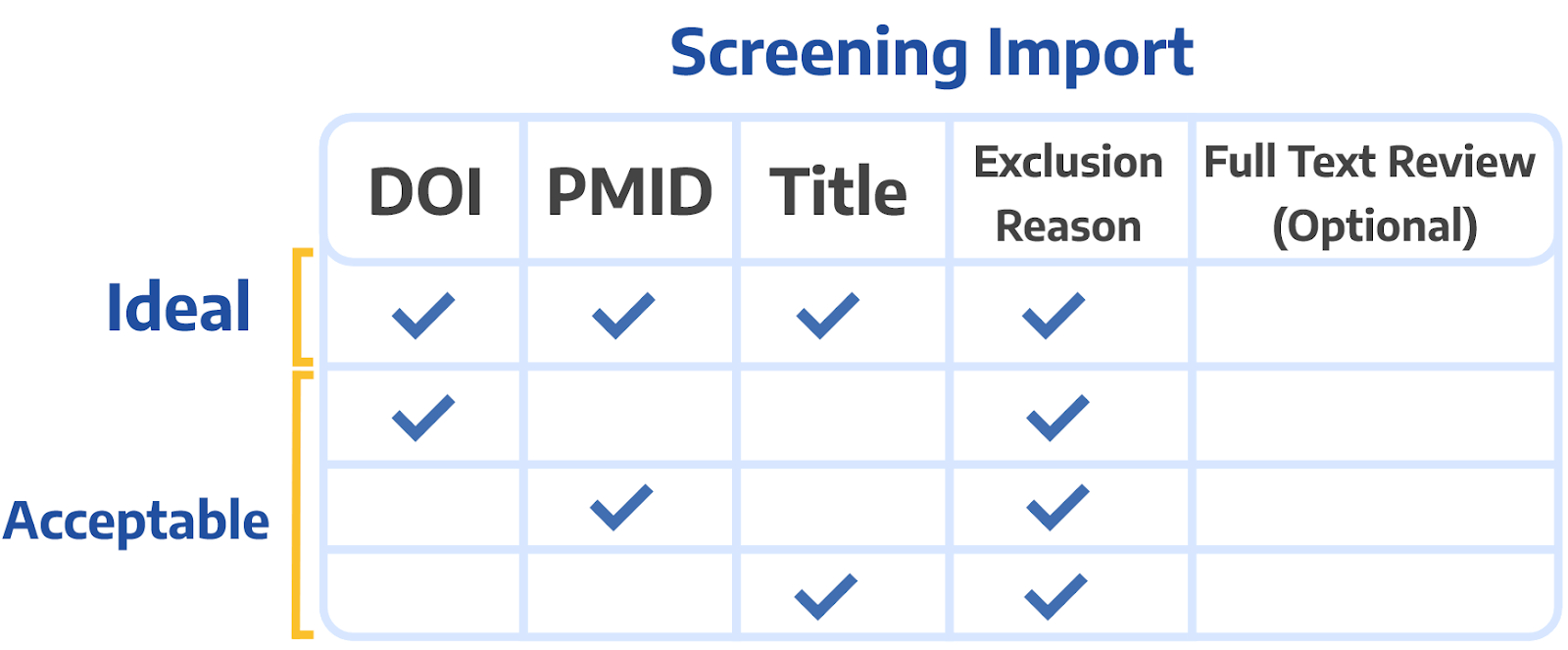
If you already have a spreadsheet of screening decisions for your studies, import them into Nested Knowledge via Settings (Screening, Import, Upload Data).
When importing spreadsheets, to be matched correctly the spreadsheet must contain:
1-3 of the following columns: Title, DOI and/or PubMed ID
Ref ID column can also be used for matching
A column titled Exclusion Reason, where any text will tell the software the record is excluded and no text will indicate the record is included
Optional: you may include a column titled “Full Text Review” to indicate if the screening decision was made using a review of the full text. “True” or “Yes” cell input indicates a full text was reviewed, “False” or “No” or no text or no column indicate a full text was not reviewed.
Tagging/Data Extraction
Studies marked included in Screening are then displayed in Tagging for data extraction. A customized tag hierarchy must be made prior to beginning Tagging and reflects the format of the spreadsheet you intend to download after data extraction. Using NK, applied tags generate interactive outputs (Qualitative Synthesis) and are downloadable as a spreadsheet.
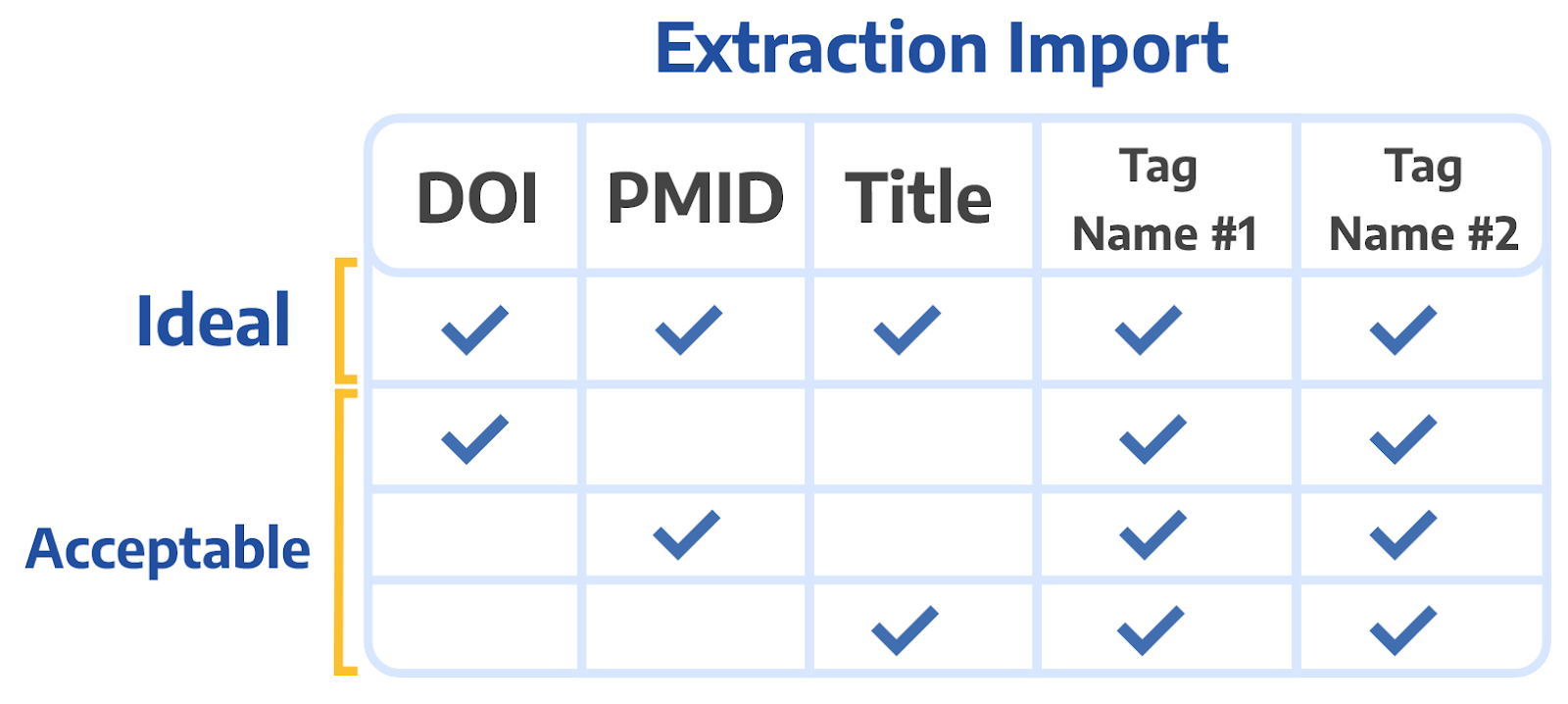
If you already have a spreadsheet of tags/extracted data for your studies, import them into Nested Knowledge via Settings (Tagging, Import, Upload Data).
When importing spreadsheets, to be matched correctly the spreadsheet must contain:
1-3 of the following columns: Title, DOI and/or PubMed ID
Ref ID column can also be used for matching
Column headers in the spreadsheet populate as tags in the hierarchy and cell content represents an applied tag
Hierarchies can be templated after creation
OpenAI GPT 3.5/4 is used to scan each record’s full texts against the customized hierarchy and identify best evidence to extract. Recommendations can be accepted individually, in bulk, and/or denied. See our Technical Disclosure of AI Systems used in Nested Knowledge.
Download a spreadsheet of all tags applied to all or filtered studies via Study Inspector. More on the remaining outputs available to download below.
One of the features of Core Smart Tags is Smart Study Type – this refers to our AI system that automatically categorises the study type
